Software security is a critical concern for modern software products. The vulnerabilities that reside in their source code could become a major weakness for enterprises that build or utilize these products, as their exploitation could lead to devastating financial consequences and reputation damages. In order to prevent security breaches, software companies have started investing on the security-by-design paradigm, i.e., on building products that are highly secure from the ground up. However, this inevitably introduces additional overheads to the software development lifecycle (SDLC), due to the extra time and effort that is required for detecting and fixing vulnerabilities that reside in the software applications under development. Hence, several mechanisms and tools have been proposed in the literature over the years to help developers and project managers better plan their security testing and fortification activities, in order to reduce the overheads added by the incorporation of the security-by-design paradigm into their workflows.
To this end, a lot of effort has been dedicated in the literature to the prediction of vulnerable software components using software attributes extracted by the source code. In these studies, researchers commonly train machine learning models based on either software metrics (e.g., cohesion, coupling, and complexity metrics) or text features, in order to predict whether the analyzed component is potentially vulnerable or not. However, these approaches do not predict the number of vulnerabilities in future versions. An indication of the expected number of vulnerabilities and the trends of their occurrences can be a very useful tool for decision makers, enabling them to prioritize their valuable time and limited resources for testing an existing software project and patching its reported vulnerabilities. For this purpose, there is a need for forecasting models that can predict the trend and the number of vulnerabilities that are expected to be discovered in a specific time horizon for a given software project.
In an attempt to address the aforementioned challenges, within the IoTAC project, and as part of the Security by Design (SSD) Platform, we built models for forecasting the future evolution of the number of vulnerabilities that a given project may have. More specifically, we empirically examined the capacity of statistical and deep learning (DL) models to forecast the future number of vulnerabilities that a software product may exhibit and we compared their performance. The high-level overview of our methodology is depicted in the figure below:
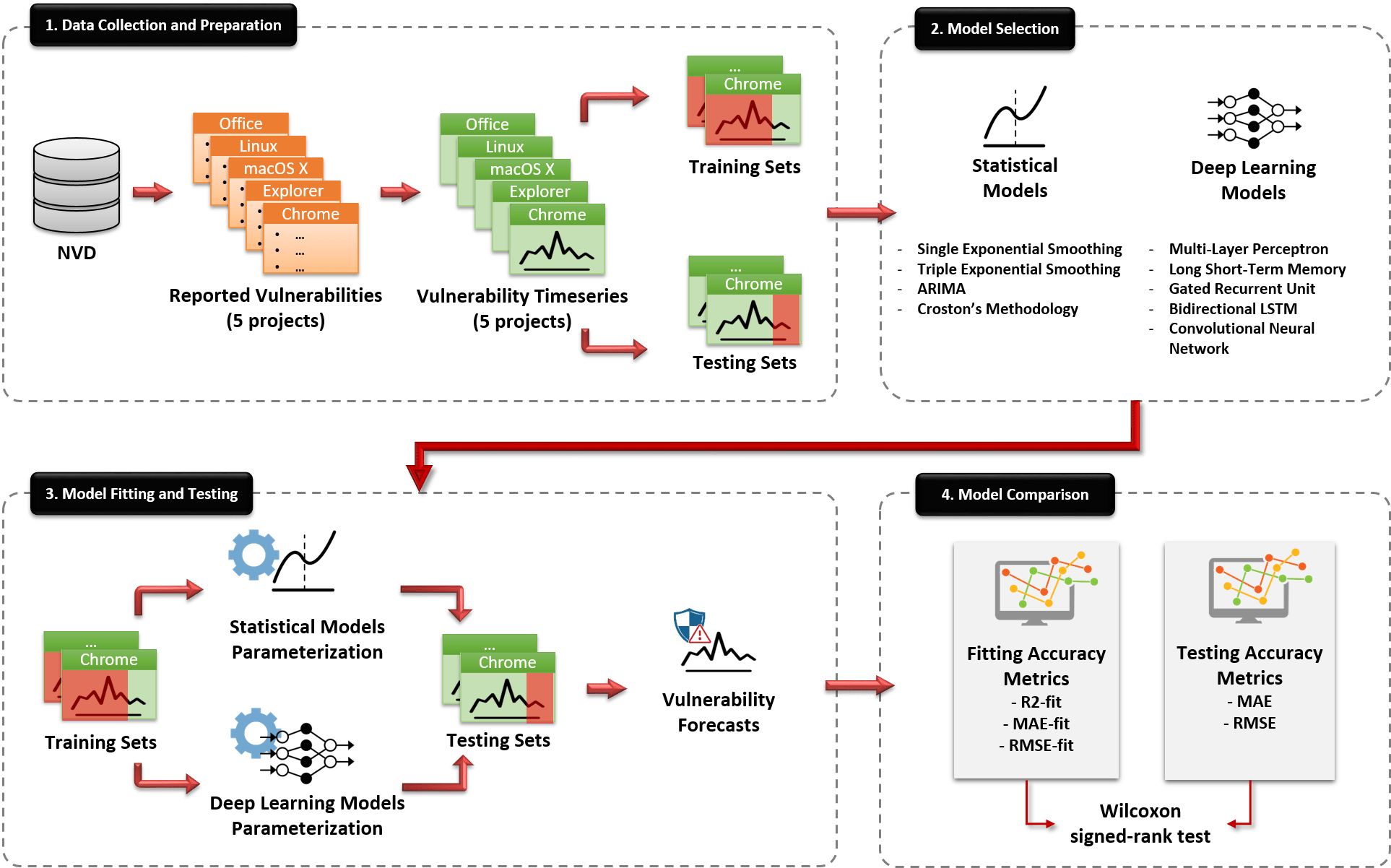 Figure 1: The high-level overview of our approach for building and evaluating the statistical and deep learning models for forecasting the evolution of software vulnerabilities
Figure 1: The high-level overview of our approach for building and evaluating the statistical and deep learning models for forecasting the evolution of software vulnerabilities
As can be seen by the figure above, in order to build the forecasting models, we initially collected the historical vulnerability data of five popular software applications (Microsoft Office, Apple macOS X, Ubuntu Linux, Internet Explorer, and Google Chrome) for a duration of 20 years from the National Vulnerability Database (NVD). These data were used in order to construct the training and testing sets that are required for building the models. Based on these data, we built several statistical models (e.g., ARIMA, Croston, etc.) and Deep Learning models (e.g., MLP, RNN, CNN, etc.) that are able to predict the future number of vulnerabilities for a horizon of 24 months, and we evaluated their performance based on their goodness-of-fit, as well as on their Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) when applied to previously unseen data. The results of the analysis are depicted in the figure below.
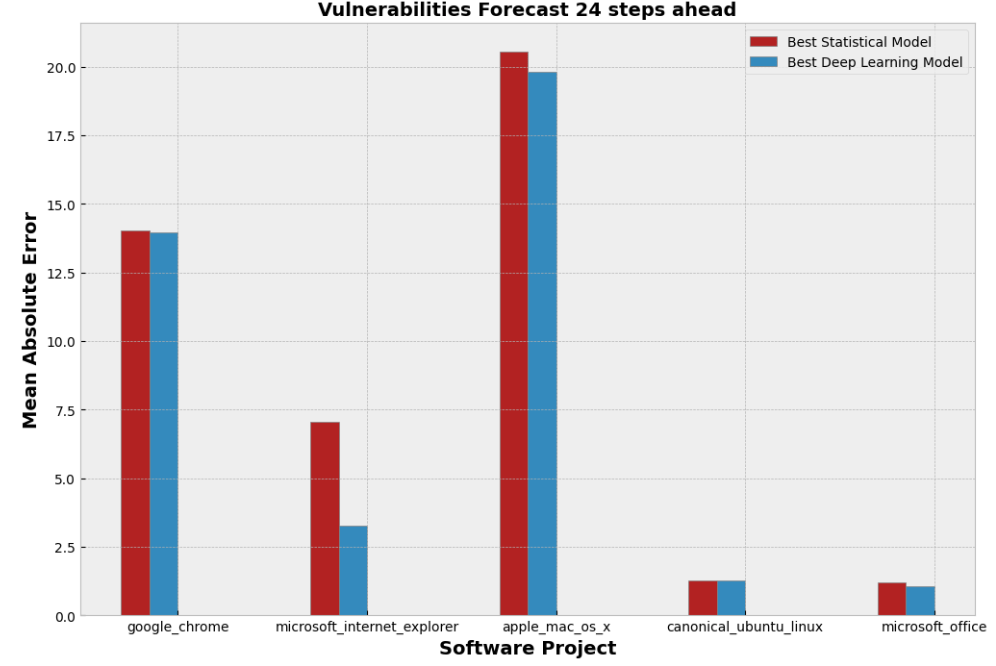 Figure 2: The Mean Absolute Error (MAE) of the best statistical and deep learning models of each studied software application
Figure 2: The Mean Absolute Error (MAE) of the best statistical and deep learning models of each studied software application
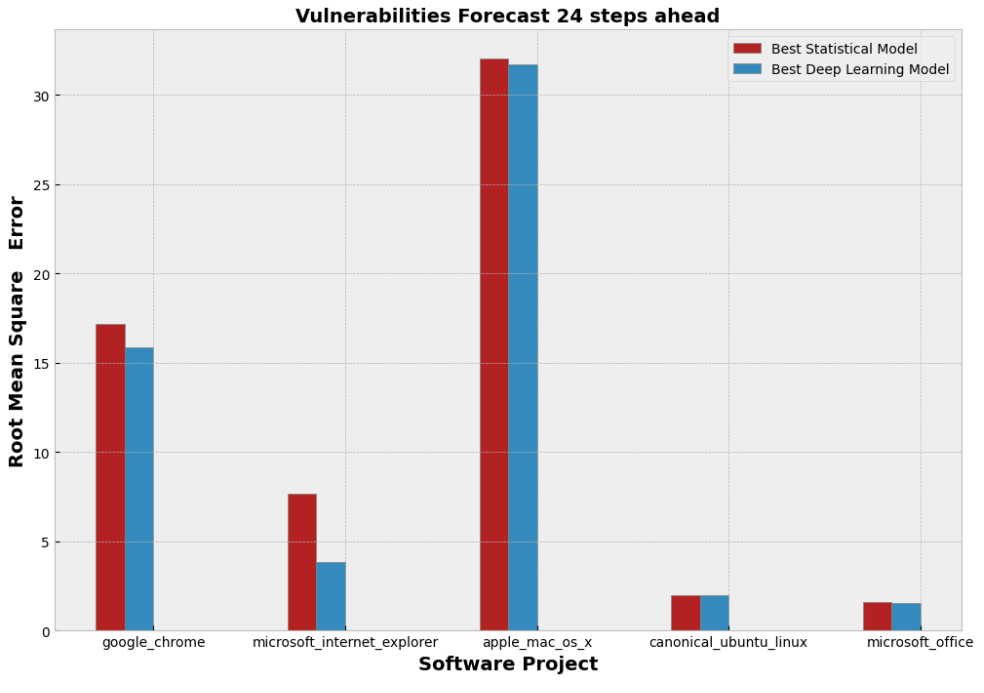 Figure 3: The Root Mean Square Error (RMSE) of the best statistical and deep learning models of each studied software application
Figure 3: The Root Mean Square Error (RMSE) of the best statistical and deep learning models of each studied software application
As can be seen from the figures above, the DL models demonstrate slightly better predictive performance compared to the statistical models in terms of their MAE and RMSE in all five studied projects. However, after applying hypothesis testing, we figured out that this difference is not observed to be statistically significant. Hence, based on the above analysis, we can state that both DL and statistical models demonstrate almost similar predictive performance. In addition to this, another interesting observation is that it seems that the capacity of the models to provide sufficient predictive performance seems to depend on the project itself rather than on the type of the selected forecasting models. More details about our work can be found in the associated published paper.




