A significant number of vulnerabilities that exist in software systems are introduced during the Requirements and Design phases of the Software Development Lifecycle (SDLC) mainly due to incorrect or vague security requirements[1]. In fact, the incorrect or vague security requirements, which are also known as design flaws, manifest themselves as actual vulnerabilities in the source code of the software system, if they are not promptly identified and fixed. Hence, there is a need for methods and tools that will enable the definition of software security requirements in a uniform, clear, and concrete way, in order to avoid mistakes and misinterpretations later on during the SDLC. Although some research endeavors have been dedicated towards this direction, their vast majority focused on introducing theoretical methodologies, reusable templates, and formal languages, which, despite their undeniable contribution to facilitating the correct specification of security requirements, they are difficult to learn and tedious to use, rendering them less adopted in practice. In fact, very limited work has been dedicated in the literature to facilitating the automatic elicitation and formal specification of security requirements, especially from requirement documents expressed in natural language, which is the format in which requirements are usually expressed in practice.
In order to address the aforementioned issues, within the context of the IoTAC project, and as part of our Software Security by Design (SSD) platform we propose a novel Software Security Requirements Specification (SSRS) mechanism, able to automatically identify the main concepts of a given set of security requirements expressed in natural language by applying syntactic and semantic analysis, and subsequently turn them into more well-structured form, i.e., ontology objects. The purpose of the SSRS component is to help software engineers formally specify security requirements in a well-defined and structured way, without having to utilize tedious templates or learn complex formal specification languages. The high-level overview of the SSRS component is illustrated in the following figure.
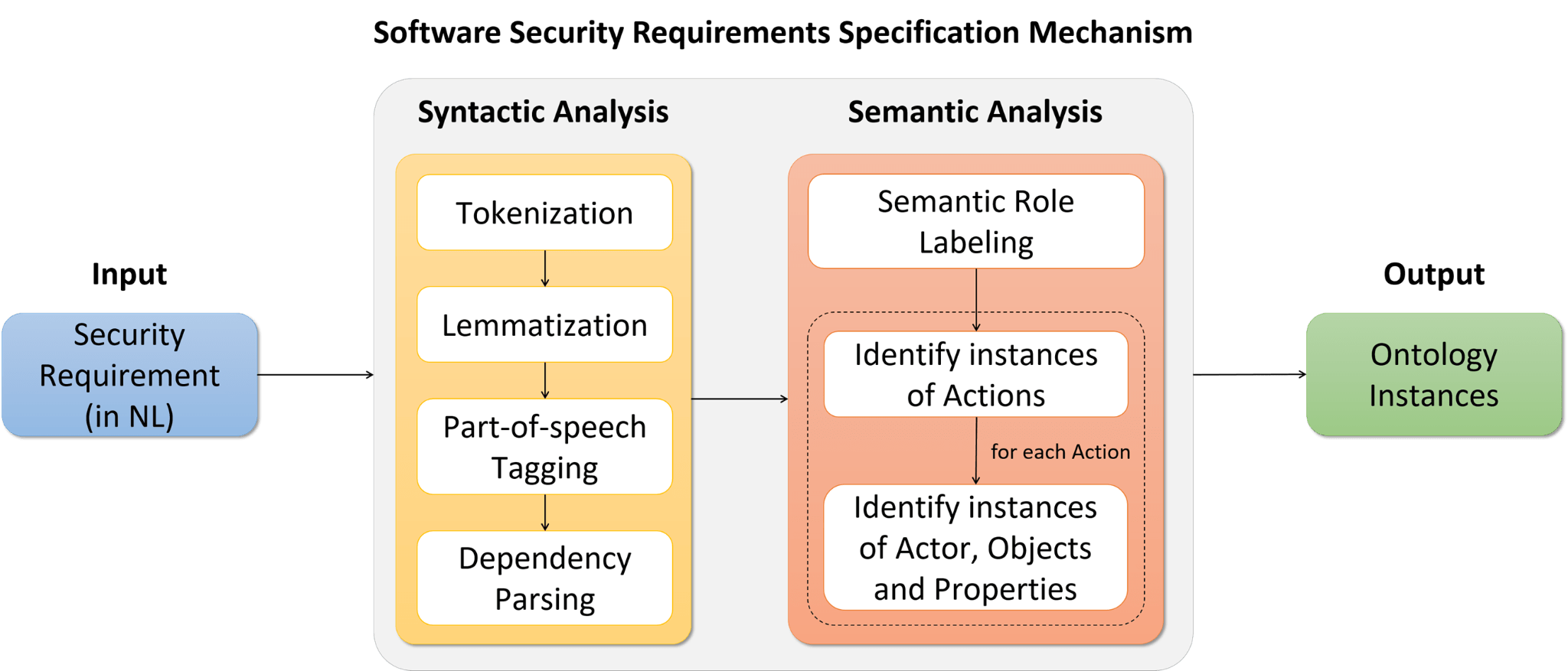
As can be seen by the figure above, the proposed mechanism receives as input security requirements expressed in natural language (i.e., pure text). Then the textual security requirements are processed, through a process that consists of two main steps, namely the Syntactic Analysis, which identifies the main grammatical terms (e.g., noun, verb, etc.) of the processed requirement along with their grammatical relationships (e.g., subject-verb-object, etc.), and the Semantic Analysis, which identifies the main semantic concepts (e.g., Action, Actor, Object, etc.) of the requirement along with their semantic relations.
The Syntactic Analysis step receives as input the requirement expressed in natural language and applies tokenization in order to split the sentence into word tokens, as well as lemmatization in order to derive the uninflected form of each word token. Subsequently, it applies part-of-speech tagging, in order to identify the grammatical category of each word and dependency parsing to determine the grammatical relations between them. For the above procedure, the Mate Tools[2] were utilized, which are well-known tools for performing syntactic analysis.
In the next step, the results of the Syntactic Analysis step, and particularly the identified grammatical terms and relations, are provided as input to the Semantic Analysis mechanism, in order to be mapped to semantic terms and semantic relationships. Initially, a semantic role labeling process is performed to assign labels to words or phrases that indicate their semantic concept in the sentence, using the semantic role labeler provided by the Mate tools. However, since this semantic role labeler is able to detect only generic thematical concepts and relations (e.g., acceptor, property, etc.), it has been extended in order to also detect the main requirement-specific concepts (i.e., Actor, Action, etc.), based on a set of custom rules. In brief, as can be seen by the figure with the overview of the SSRS component above, initially the Priority and the Action of the requirement are identified. Subsequently, for each Action, the associated Actor and Object are identified. Finally, for each identified Object, several Properties (e.g., requirement prerequisites, etc.) are detected and reported.
All the identified requirement concepts are stored in a dedicated Ontology, the Security Requirements Knowledge Base. The schema of the aforementioned ontology is illustrated in the following Figure.
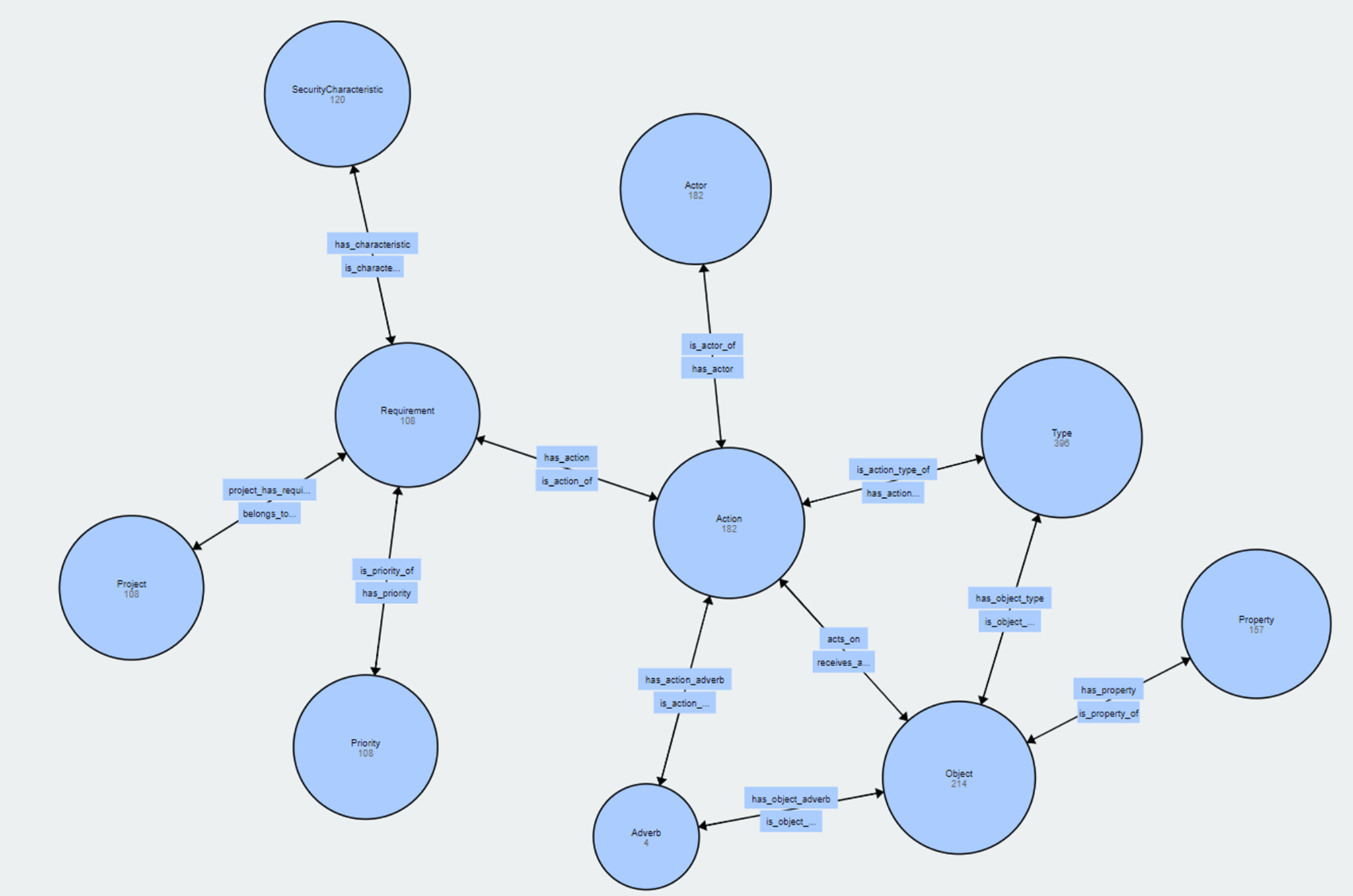
As can be seen by this figure, the ontology captures the main concepts of a security requirement along with their relationships. The ontology is an important element of the SSD Platform, as it forms the reference point for the verification and validation of user-defined security requirements, as well as of the requirement adherence check mechanism that will be developed. It should be noted that the ontology along with the security requirements that will be collected throughout the project will be made publicly available in order to facilitate future research.
[1] G. McGraw, “Software security,” IEEE Security & Privacy, 2004
[2] https://code.google.com/archive/p/mate-tools/




