1. Vulnerability Prediction – Importance and Challenges
Vulnerability prediction is responsible for the identification of security hotspots, i.e., software components (e.g., classes) that are likely to contain critical vulnerabilities. For the identification of potentially vulnerable software components, vulnerability prediction models (VPM) are constructed, which are mainly machine learning models that are built based on software attributes retrieved primarily from the source code of the analyzed software (e.g., software metrics, text features, etc.). The results of the vulnerability prediction models are highly useful for developers and project managers, as they allow them to better prioritize their testing and fortification efforts by allocating limited test resources to high-risk (i.e., potentially vulnerable) areas.
Text mining-based VPMs have demonstrated the most promising results in the related literature [1]. The first attempts in the field of text mining vulnerability prediction focused on the concept of Bag-of-Words (BoW) as a method for predicting software vulnerabilities using text terms and their respective appearance frequencies in the source code. Researchers have recently shifted their focus from simple BoW to more complex approaches, investigating whether more complex textual patterns in source code can lead to more accurate vulnerability prediction. In particular, a common approach that is adopted recently is the transformation of the source code into word token sequences and their utilization of deep neural networks capable of learning data sequences (e.g., Recurrent Neural Networks).
Since neural networks operate on numerical data, the token sequences need to be properly transformed. In the literature, word embedding vectors are widely used for this purpose. Word embedding refers to the representation of words for text analysis, which is typically in the form of a real-valued vector that encodes the meaning of the word in such a way that words that are close in the vector space are expected to have similar meanings. Existing VPMs follow mainly two different approaches for embedding the tokens into vectors, either by training the embedding layer alongside the vulnerability predictor, or by using an external word embedding algorithm (e.g., word2vec) to generate the vector representations of the tokens and use the produced embeddings as input to the vulnerability predictor (which is trained separately). Although both approaches have their merits, limited focus has been given on comparing them with respect to their ability to lead to accurate vulnerability predictions.
The aim of the research is to demonstrate the value of sophisticated embedding algorithms (e.g., word2vec, fast-text) in text mining-based vulnerability prediction by showcasing their contribution to the effectiveness and efficiency of the VPMs and comparing them to the use of a trainable embedding layer that updates its values during VP classifier training.
2. IoTAC Vulnerability Prediction Models
Within the context of the IoTAC project, as part of the Software Security-by-Design (SSD) Platform, we developed vulnerability prediction models based on deep learning, utilizing as input the sequences of word tokens that reside in the source code of the component, and word embedding vectors for their effective representation. We have focused both on utilizing a trainable embedding layer and external word embedding algorithms, in an attempt to evaluate which of the two option leads to better predictive performance. A high-level overview of the proposed models is illustrated in the figure below.
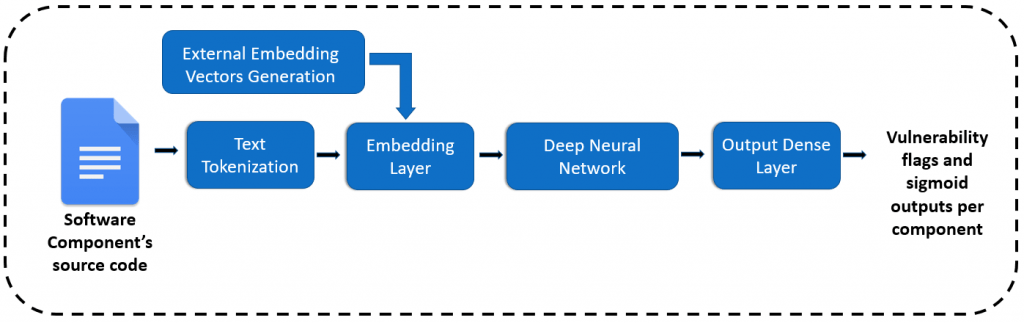
Figure 1 – The high-level overview of the Vulnerability Prediction Models of the IoTAC project
As illustrated in the figure above, the source code of a software component is provided as input to the model and, subsequently, text tokenization is applied in order to extract the word tokens and construct their corresponding sequence. Then, the token sequences are transformed into numerical vector, through the utilization of word embedding. The derived word embedding vectors constitute the word embedding layer, i.e., the input layer of the DNN, which is the core element of the model. As already stated, for constructing the models, we consider both internal word embeddings (i.e., a word embedding layer that is trained along with the prediction model) and two popular word embedding algorithms to generate the word embedding vectors, namely word2vec[1] and fast-text[2].
The output of the model is a vulnerability flag (i.e., a binary value between 0 and 1) indicating whether the given component is potentially vulnerable (i.e., 1) or not (i.e., 0), and a vulnerability score (i.e., a continuous value within the [0,1] interval) denoting how likely it is for the component to be vulnerable. The developers can utilize the output of these models for prioritizing their testing and fortification efforts. For instance, the software components can be ranked based on their vulnerability score and the refactoring activities can start from those components that are more likely to contain vulnerabilities.
The evaluation results led to some interesting conclusions regarding the effectiveness of word embeddings in vulnerability prediction. As can be seen by the figure below, all the models that are built utilizing word token sequences are in general effective in predicting the existence of vulnerabilities in software. In addition to this, the utilization of external word embedding algorithms and specifically of the word2vec leads to better predictive performance, indicating that the utilization of external word embeddings may be a more promising solution for vulnerability prediction.
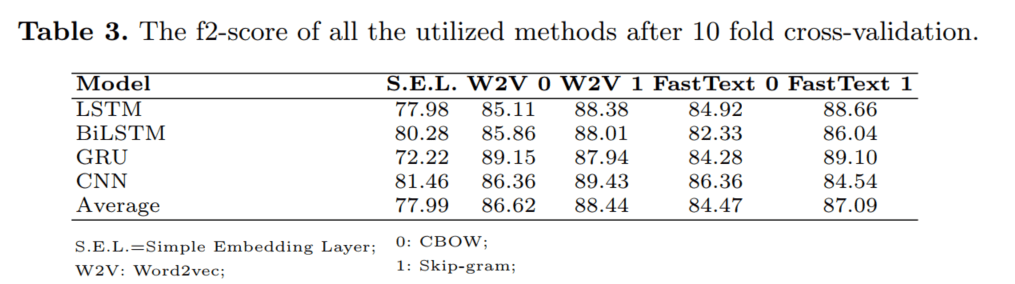
Figure 2 – Evaluation results of the text mining-based Vulnerability Prediction Models using “internal” and “external” embedding vectors
More information about the work presented in this blog post, including information about the construction of the machine learning models and the evaluation results, can be found in a recent publication that is available here. More information about the SSD Platform can be found in our previous post.
[1] https://radimrehurek.com/gensim/models/word2vec.html
[2] https://radimrehurek.com/gensim/models/fasttext.html
References
[1] S. Chakraborty, R. Krishna, Y. Ding, and B. Ray, “Deep learning based vulnerability detection: Are we there yet,” IEEE Transactions on Software Engineering, 2021.




